وبلاگ چت روم کامپیوتر و شبکه در سایت الفور

بینایی رایانهای یا بینایی کامپیوتری (Computer vision) یا بینایی ماشینی (Machine vision) یکی از شاخههای مدرن، و پرتنوٌع هوش مصنوعیست که با ترکیب روشهای مربوط به پردازش تصاویر[1] و ابزارهای یادگیری ماشینی[2] رایانهها را به بینایی اشیاء، مناظر، و "درک" هوشمند خصوصیات گوناگون آنها توانا میگرداند.
بینایی ماشینی را میشود یکی از مصادیق و نمونههای بارز زمینه مادر و اصلیتر کاوشهای ماشینی دادهها بهحساب آورد که در آن دادهها تصاویر دوبعدی یا سهبعدی هستند، که آنها را با هوش مصنوعی مورد آنالیز و ادراک قرار میدهیم.
تشخیص حضور و/یا حالت شیء در یک تصویر. به عنوان مثال:
پیگیری اشیاء شناخته شده در میان تعدادی تصویر پشت سر هم. به عنوان مثال:
ساختن یک مدل از یک تصویر/تصویر متحرک. بهعنوان مثال:
مشحص کردن مکان و حرکت خود دوربین به عنوان عضو بینایی رایانه. بهعنوان مثال:
یک سامانه نوعی بینایی رایانهای را میتوان به زیرسامانههای زیر تقسیم کرد:
تصویر یا دنباله تصاویر با یک سامانه تصویربرداری(دوربین، رادار، لیدار، سامانه توموگرافی) برداشته میشود. معمولاً سامانه تصویربرداری باید پیش از استفاده تنظیم شود.
در گام پیشپردازش، تصویر در معرض اَعمال "سطح پایین" قرار میگیرد. هدف این گام کاهش نوفه (کاهش نویز - جدا کردن سیگنال از نویز) و کمکردن مقدار کلی داده ها است. این کار نوعاً با بهکارگیری روشهای گوناگون پردازش تصویر(دیجیتال) انجام میشود. مانند:
هدف از استخراج ویژگی کاهش دادن بیشتر دادهها به مجموعهای از ویژگیهاست، که باید به اغتشاشاتی چون شرایط نورپردازی، موقعیت دوربین، نویز و اعوجاج ایمن باشند. نمونههایی از استخراج ویژگی عبارتاند از:
هدف گام ثبت برقراری تناظر میان ویژگیهای مجموعه برداشت شده و ویژگیهای اجسام شناختهشده در یک پایگاه دادههای مدل و/یا ویژگیهای تصویر قبلی است. در گام ثبت باید به یک فرضیه نهایی رسید. چند روش این کار عبارتاند از:
 نوشته شده توسط لادن در یکشنبه 90/2/18 و ساعت 9:21 صبح | نظرات دیگران()
نوشته شده توسط لادن در یکشنبه 90/2/18 و ساعت 9:21 صبح | نظرات دیگران()الگوریتم زنبور شامل گروهی مبتنی بر الگوریتم جستجو است که اولین بار در سال 2005 توسعه یافت ؛ این الگوریتم شبیه سازی رفتار جستجوی غذای گروههای زنبور عسل است. در نسخه ابتدایی این الگوریتم، الگوریتم نوعی از جستجوی محلی انجام می دهد که با جستجوی کتره ای{Random } ترکیب شده و می تواند برای بهینه سازی ترکیبی {زمانی که بخواهیم چند متغیر را همزمان بهینه کنیم.}یا بهینه سازی تابعی به کار رود.
جستجوی غذا در طبیعت
یک کلونی زنبور عسل می تواند در مسافت زیادی و نیز در جهت های گوناگون پخش شود تا از منابع غذایی بهره برداری کند.
قطعات گلدار با مقادیر زیادی نکتار و گرده که با تلاشی کم قابل جمع آوری است،به وسیلهی تعداد زیادی زنبور بازدید می شود؛ به طوری که قطعاتی از زمین که گرده یا نکتار کمتری دارد، تعداد کمتری زنبور را جلب می کند.
پروسه ی جستجوی غذای یک کلونی به وسیله ی زنبورهای دیده بان آغاز می شود که برای جستجوی گلزار های امید بخش {دارای امید بالا برای وجود نکتار یا گرده}فرستاده می شوند.
زنبورهای دیده بان به صورت کتره ای{Random } از گلزاری به گلزار دیگر حرکت می کنند.
در طول فصل برداشت محصول{گل دهی}، کلونی با آماده نگه داشتن تعدادی از جمعیت کلونی به عنوان زنبور دیده بان به جستجوی خود ادامه می دهند. هنگامی که جستجوی تمام گلزار ها پایان یافت، هر زنبور دیده بان ، بالای گلزاری که اندوخته ی کیفی مطمئنی از نکتار و گرده دارد، رقص خاصی را اجرا می کند.
این رقص که به نام "رقص چرخشی"{حرکتی مانند حرکت قرقره} شناخته می شود، اطلاعات مربوط به جهت تکه گلزار{نسبت به کندو}، فاصله تا گلزار و کیفیت گلزار را به زنبور های دیگر انتقال می دهد. این اطلاعات زنبور های اضافی و پیرو را به سوی گلزار می فرستد.
بیشتر زنبور های پیرو به سوی گلزار هایی میروند که امید بخش تر هستند و امید بیشتری برای یافتن نکتار و گرده در آنها، وجود دارد.
وقتی همه ی زنبور ها به سمت ناحیه ای مشابه بروند، دوباره به صورت کتره ای {Random } و به علت محدوده ی رقصشان در پیرامون گلزار پراکنده می شوند تا به موجب این کار سرانجام نه یک گلزار ، بلکه بهترین گل های موجود درون آن تعیین موقعیت شوند.
الگوریتم
الگوریتم زنبور هر نقطه را در فضای پارامتری_ متشکل از پاسخ های ممکن_به عنوان منبع غذا تحت بررسی قرار می دهد."زنبور های دیده بان"_ کارگزاران شبیه سازی شده _به صورت کتره ای{Random } فضای پاسخ ها را ساده می کنند و به وسیله ی تابع شایستگی کیفیت موقعیت های بازدید شده را گزار ش می دهند. جواب های ساده شده رتبه بندی می شوند، و دیگر "زنبورها" نیروهای تازه ای هستند که فضای پاسخ ها را در پیرامون خود برای یافتن بالا ترین رتبه محل ها جستجو می کنند{که "گلزار" نامیده می شود} الگوریتم به صورت گزینشی دیگر گلزار ها را برای یافتن نقطه ی بیشینه ی تابع شایستگی جستجو می کند.
کاربرد ها
برخی کاربرد های الگوریتم زنبور در مهندسی:
آموزش شبکه عصبی برای الگو شناسی
زمان بندی کارها برای ماشین های تولیدی
دسته بندی اطلاعات
بهینه سازی طراحی اجزای مکانیکی
بهینه سازی چند گانه
میزان کردن کنترل کننده های منطق فازی برای ربات های ورزشکار
__________________
بهینه سازی کلونی زنبورها
حرکتی مساعی گونه برای حل مسائل حمل و نقل و جابجایی پیشرفته
چکیده
سیستمهای طبیعی مختلفی به ما یاد میدهند که ارگانیسمهای خارجی بسیار ساده ایی توان تولید سیستمهایی با قابلیت انجام کارهایی بسیار پیچیده به کمک برهم کنشهای پویا با هم را دارند.
متاهیوریستیک (ابرکشف) کلونی زنبورها (BCO) در این مقاله آورده شده است.کلونی مصنوعی زنبورها در پاره ایی نزدیک به هم و در مقایسه با کلونی زنبورهای طبیعی , متفاوت عمل میکنند.
BCO به همان میزان که قابلیت حل مسائل ترکیبی قطعی را دارد , قادر به حل مسائل ترکیبی ایی است که دارای عدم قطعیت نیز میباشند.
توسعه ی الگوریتم کشف کننده ی جدید برای حل مسئله ی Ride-Matching به کمک راه پیشنهاد شده (استفاده از کلونی زنبورها) راهی روشنگر برای نشان دادن قابلیتهای این روش محسوب میشود.
1.معرفی
شمار زیادی از مدلهای مهندسی و الگوریتمهایی که برای حل مسائل پیچیده به کار میرود بر اساس کنترل و مرکزگرایی بنا شده اند.برخی از سیستمهای طبیعی (کلونی های حشرات اجتماعی) به ما یاد میدهند که یک سری ارگانیسمهای ساده ی خارجی قابلیت تولید سیستمهایی را دارند که به کمک بر هم کنشهای پویا قابلیت انجام اعمال بسیار پیچیده را دارند.
گروه زنبورها به خاطر استقلال داخلی کلونی و عملکردهای توزیع شده و سیستم درون سازمانی یکی از بهترین کلونی ها برای توضیح این مسئله شناحته شده است.
در سالهای اخیر محققان برای تولید سیستمهای جدید مصنوعی (در حیطه ی هوش مصنوعی) شروع به تحقیق درباره ی طرز رفتار حشرات اجتماعی کرده اند.
BCO ( Bee Colony Optimization) که مسیر جدیدی را در هوش جمعی بررسی میکند در این مقاله بررسی شده است.هدف اصلی این مقاله بررسی این امکان است که به کمک سیستم مصنوعی زنبورها بتوان قدمی را در پیدا کردن راه حلهایی جامع برای حل مسائلی که با عدم قطعیت مواجه هستند برداشت.
ادامه ی مقاله در قسمتهای دوم و سوم آمده است.قسمت دوم به توضیح BCO میپردازد در حالیکه قسمت سوم به مطالعه ی موضوعی مربوط به مسئله Ride-Matching میپردازد.
.The Bee Colony Optimization : The New Computational Paradigm2
حشرات اجتماعی (زنبورعسل , زنبور معمولی , مورچه ها , موریانه ها) برای میلیونها سال بر روی کره زمین زندگی کرده اند , آشیانه های مختلف و بسیاری از ساخته های پیچیده تر ساخته اند و آذوقه شان را سازماندهی کرده اند.کلونی حشرات اجتماعی بسیار انعطاف پذیر محسوب میشود و به خوبی قابلیت همساز شدن با محیط جدید را دارند.این انعطاف پذیری این امکان را به کلونی میدهد تا بتواند حتی با مواجه شدن با شرایط سخت و مشکلات , به زندگی خود ادامه دهد.
پویاگرایی جمعیت حشرات نتیجه ایی از عملکردها و تعاملات بین حشرات با یکدیگر و با محیط اطراف است.تعاملات بین حشرات بر اساس یک سری عوامل فیزیکی و شیمیایی امکان پذیر شده است.محصول نهایی این تعاملات و عملکردها , رفتار اجتماعی این گونه حشرات محسوب میشود.
مثالی برای چنین رفتارهایی , رقص مورچه ها در هنگام جمع آوری محصول است.مثال دیگری برای این حالت ترشح فنومون (هورمون جنسی) در مورچه هاست که موجب راه گذاری برای مورچه های دیگر خواهد شد.این سیستمهای ارتباطی بین حشرات مختلف موجب به وجود آمدن مقوله ایی به نام "هوش اشتراکی" میشود.به این معنی که حشرات فوق به هنگام قرار گرفتن در کنار یکدیگر دارای فاکتوری هوشمند میشوند که در غیاب یکدیگر قادر به انجام چنین کاری نیستند.
2.1 : Bees In Nature
سیستم سازمانی زنبورها بر اساس یک سری قوائد ساده ی خارجی حشرات بنا شده است.با اینکه نژادهای بسیاری از حشرات مختلف بر روی کره ی زمین موجود هستند و همین باعث تفاوتهایی در الگوی رفتاری آنها میشود , ولی با اینحال این سری حشرات اجتماعی را میتوان دارای قابلیت حل مسائل پیچیده دانست.بهترین مثال برای این حالت روند تولید نکتار (شهد) محسوب میشود که در نوع خود یک فرایند ساماندهی شده ی پیشرفته محسوب میشود.هر زنبور ترجیح میدهد که راه قبلی زنبور هم کندوی خود را دنبال کند تا اینکه خود به دنبال گل جدید بگردد.
هر کندوی زنبور عسل دارای مکانی معروف به سالن رقص است که در آنجا زنبورها با انجام حرکتی خاص , هم کندوییهای خود را راضی میکنند تا راه آنها را برای رسیدن به گلها برگزینند.اگر یک زنبور تصمیم بگیرد که به دنبال نکتار برود , با انتخاب زنبور هم کندوی رقاص خود , راه قبلی را دنبال میکند تا به گل برسد.با رسیدن زنبور به گلها و جمع آوری شهد قادر به انجام کارهای زیر است :
الف : منبع غذا را رها کند و دوباره به دنبال زنبور رقصانی بگردد تا بتواند منبعی جدید پیدا کند.
ب : خود به دنبال منابع غذایی جدید بگردد.
ج : در کندو اقدام به رقصیدن کرده و زنبورهای جدیدی را به دنبال خود بکشاند.
بر اساس احتمالات اندازه گیری شده , زنبور اقدام به انجام یکی از حالات بالا میکند .در مکان رقص , زنبورها اقدام به پیشنهاد مکانهای مربوط به جمع آوری نکتار به دیگران میکنند.مکانیزم انتخاب یک زنبور توسط زنبوری دیگر هنوز شناخته شده نیست ولی تا به امروز روشن شده است که این امر بیشتر مربوط به کیفیت نکتار پیدا شده توسط زنبور رقاص است.
لوسیچ و تدوروویچ اولین کسانی بودند که از رویه های پایه و ساده ی زنبوری برای حل کردن مسائل ترکیبی بهینه سازی استفاده کردند.آنها سیستم زنبوری (BS) را معرفی کردند و از آن برای حل مساله ی معروف Travelling Salesman استفاده کردند.در ادامه به استفاده های BCO در حل مسائل پیشرفته اشاره خواهیم کرد.
در کلونی مصنوعی طراحی شده توسط ما شباهتها و تفاوتهایی با کلونهای واقعی زنبورها در طبیعت وجود دارد.در ادامه به معرفی FBS (Fuzzy Bee System) میپردازیم که قادر به حل مسائل ترکیبی *طرح شده توسط انسانها* است.به کمک FBS , Agent ها در ارتباطات با همدیگر از قوانین تقریبی دلیلگرایی و منطق Fuzzy استفاده میکنند.
2.2 : The Bee Colony Optimization Metaheuristic
در BCO , مامورهایی که ما به آنها "زنبور مصنوعی" میگوییم با همدیگر اجتماع میکنند تا بتوانند قادر به حل مسائل مشکلتر باشند.تمامی زنبورهای مصنوعی در ابتدای فرایند جستجو , در کندوی اصلی قرار دارند.در فرایند جستجو نیز , زنبورهای مصنوعی به طور کاملا مستقیم با یکدیگر ارتباط برقرار میکنند.هر زنبور مصنعوی یک سری حرکات محلی خاص انجام داده و به کمک آنها قادر خواهد بود تا راه حلی را بری مشکل فعلی خود پیدا کند.
این زنبورها تک تک راه حلهای کمکی و زیرپایه ایی را ارائه میدهند تا در آخر با ادغام این راه حلها , راه حل اصلی برای حل مسئله ی ترکیبی به دست بیاید.
روند جستجو از تکرارهای پشت سر هم تشکیل شده است.اولین تکرار زمانی پایان میابد که اولین زنبور راه حل زیر پایه ی خود را برای حل مسئله ی اصلی ارائه دهد.
بهترین راه حل زیرپایه در خلال اولین تکرار انتخاب شده و پس از آن , تکرار دوم شروع خواهد شد.در تکرار دوم , زنبورهای مصنوعی شروع به پیدا کردن راه حلی جدید برای مسئله ی زیر پایه میکنند و...
در پایان هر تکرار حداقل یک و یا چند راه حل ارائه شده وحود دارد , که آنالیست مقدار همگی آنها را مشخصی میکند.
به هنگام حرکت در فضا , زنبورهای مصنوعی ما یکی از دو حرکت "حرکت به سمت جلو" و یا "حرکت به سمت عقب" را انجام میدهند.
به هنگام "حرکت به سمت جلو" زنبورها راه و روشهای جدیدی را برای حل مسئله پیدا میکنند.آنها اینکار را به کمک یک سری جستجوهای شخصی و اطلاعات بدست آمده ی گذشته انجام میدهند.
بعد از آن , زنبورها عمل "حرکت به سمت عقب" را انجام میدهند که همان برگشتن به کندوی اصلی است.در کندو همگی زنبورها در یک فرایند "تصمیم گیری" شرکت میکنند.ما در نظر میگیریم که هر زنبوری قابلیت درک و دریافت اطلاعات زنبورهای دیگر را بر اساس کیفیت دارد.به کمک این روش , زنبورها این قابلیت را دارند که با استفاده از اطلاعات دیگران , راههای بهتر حل مسئله را پیدا کنند.
براساس اطلاعات جدیدی که در مورد کیفیت راه حل به دست می آید , زنبور میتواند تصمیم بگیرد که :
الف) منبع راه حل خود را رها کرده و در سالن رقص به دنبال کسی بگردد که منبعی با کیفیت بیشتر در اختیار دارد.
ب) بدون اینکه کسی را جذب کند , دوباره به سراغ منبع راه حل خود برود.
ج)در سالن رقص با انجام حرکاتی خاص (رقصیدن) سعی در جمع کردن زنبورهای دیگر به دور خود داشته باشد.
بر اساس میزان کیفیتی که زنبور از منبع خود به دست می آورد , فاکتوری به نام "وفاداری" در وی بوجود می آید که در واقع همان وفاداری به راهی است که خود زنبور انتخاب کرده است.بار دومی که زنبورهای مصنوعی برای پیدا کدن راه حل مسئله به حرکت در می آیند , اینبار سعی در پیدا کردن راههای جدیدی برای حل مسوله دارند و بعد از اینکار دوباره عمل "حرکت به سمت عقب" را انجام داده و به کندو برمیگردند و دوباره در کندو در بحثی که در مورد پیدا کردن بهترین راه شکل گرفته , شرکت میکنند.
این روند زمانی پایان میابد که یک راه حل تقریبا کامل برای مسئله پیدا شود.
مثل برنامه نویسی پویا , BCO نیز میتواند مسائل ترکیبی بهینه سازی را در هر مرحله (تکرار) به میزانی حل کند.هر کدام از مراحل مشخص شده دارای یک مقدار بهینه سازی خاص است.بگذارین اشاره کنیم که :
ST={st1 + st2 + … + stm}
همانطور که میبینید هر Stage (مرحله) شامل یک سری مراحل از قبل انتخاب شده است.در ادامه میبینید که به کمک کمیت B ما تعدا زنبورهایی را که در این فرایند شرکت میکنند را مشخص میکنیم و به کمک I , تعداد کل مراحل (تکرار) هایی را که انجام میپذیرند را نشان میدهیم.مجموعه ی تمامی راه حلهای زیرپایه را نیز به کمک Sj نشان میدهیم که در آن j دارای مقادیر 1 تا m میباشد.
در زیر کد پیش ساخت BCO را مشاهده میکنید :
الف) شروع : مشخص کردن تعداد زنبورها (B) و تعداد تکرارها (I). مشخص نمودن تعداد مراحل (ST).پیدا کردن هر گونه راه حل قابل حل x از مسئله.
این راه حل در واقع بهترین و اولین راه حل انتخاب توسط ما خواهد بود.
ب) Set i:=1 , Until i=I و تکرار کن مراحل بعدی را
ج) Set j:=m , Until j=m و تکرار کن مراحل بعدی را
حرکت به سمت جلو : رفت : به زنبورها این امکان را میدهد که از کندو بیرون آمده و قابلیت انتخاب B راه حل را از مجموعه ی راه حلهای زیرپایه Sj در STj داشته باشند.
حرکت به سمت عقب : برگشت : تمامی زنبورها را به کندو برمیگرداند.به زنبورها این اجازه را میدهد که اطلاعات خود را در مورد کیفیت راه حلهای دیگران و خود به اشتراک بگذارند و بدین طریق تصمیم بگیرند که منبع خود را رها کرده یا بدنبال کسی دیگر بیفتند یا به تنهایی به منبع خود برگردند و یا با رقصیدن دیگران را مشتاق دنبال کردن منبع خود کنند.
Set j:=j+1
د)اگر بهترین راه حلی (Xi) که در I امین تکرار بدست آمد , بهتر از بهترین راه اخیر بدست آمده بود , آنگاه فاکتور بهترین راه حل را به روز میکنیم : X:=xi
ه) 1Set i:=i+
بطور کل حرکتهای جلویی و عقبی در BCO میتوانند نقش فرعی را بگیرند به این معنی که تا زمانیکه یکی از فاکتورهای مهم کامل نشده است , این دو به کار خود ادامه دهند.این فاکتور مهم به عنوان مثال میتواند "بیشترین مقدار رفت و برگشت ها" و یا برخی دیگر از موارد مورد نظر توسط خود اپراتور باشد.
در BCO , زیر مدلهای مختلفی که به توصیق چگونگی حالات زنبورها میپردازد و یا منطق گرایی آنها را مشخص میکند به راحتی قابلیت توسعه و تست شدن را دارند.به این معنی که الگوریتمهای متفاوتی از BCO را میتوان طراحی کرد.
این مدلها میتوانند به توصیف چگونگی ترک کردن منبع اولیه توسط زنبورها , ادامه دادن رفت و برگشت بین کندو و منبع توسط زنبور و یا چگونگی رقصیدن زنبور برای جمع کردن دیگر زنبورها به دود خود را توضیح دهند.
2.3 : The Fuzzy Bee System
زنبورها در فرایند پیدا کردن بهترین راه حل با مشکلات تصمیم گیری مختلفی مواجه میشوند.مشکلات زیر برخی از مشکلات رایج بین آنهاست :
الف) راه حل زیرپایه ی بعدی که باید به راه حل اصلی اضافه شود چیست ؟
ب) آیا باید راه حل زیرپایه ی فعلی را رها کرد و به دنبال راه حل زیرپایه ی جدیدی رفت ؟
ج)آیا باید به گسترش راه حل زیرپایه ی فعلی ادامه داد ولی فعلا بدنبال دیگر زنبورها نرفت ؟
بسیاری از مدلهای تصمیم گیری بر اساس ابزارهای مدلینگ مختلفی به وجود آمده اند.این حالات کاملا منطقی و عقلی هستند و بر اساس این اطلاعات بوجود آمده اند که ماموران تصمیم گیر (Decision Maker Agents) مامورانی با داشتن بیشترین اطلاعات هستند و همیشه بهترین راه حل را برای پایان دادن به حل مسئله در نظر میگیرند.برای اینکه بتوان مدلهای حل مسئله ی مختلفی را بوجود آورد محققان شروع به استفاده از راههای بی قاعده تری کردند.
مفهوم ساده ی منطق فازی (Fuzzy) که توسط "زاده" معرفی شد قابلیت بهتری در توضیح مسائلی که با عدم قطعیت ادغام شده اند را دارد.با توجه به اطلاعات فوق , ما در انتخاب اینکه منطق زنبورها بر چه اساسی صورت میگیرد , از منطق فازی استفاده میکنیم.زنبورهای مصنوعی ما از منطق گرایی تقریبی و منطق فازی برای انجام اعمال خود استفاده میکنند.
به هنگام دادن راه حلهای زیرپایه ی جدید به زنبور مصنوعی , زنبور حالتهای زیر را برای برقراری ارتباط با راه حل زیرپایه ی فوق در نظر میگیرد : کم جاذبه , جذاب , خیلی جذاب
همچنین ما در نظر میگیریم که یک زنبور مصنوعی میتواند مقادیر خاصی را مانند "کوتاه" , "متوسط" و "بلند" و یا "ارزان" , "متوسط" و "گران" در نظر بگیرد.
2.3.1 : Calculating The Solution Component Attractiveness and Choice Of The Next Solution Component To Be Added To The Partial Solution
الگوریتم منطق تقریبی برای حل کردن مسئله ی جذابیت , از قوانین زیر تشکیل شده است :
اگر مقادیر بدست آمده از راه حل زیر پایه خیلی خوب باشد
آنگاه راه حل بدست آمده خیلی جذاب است.
هدف و امتیاز اصلی استفاده از از این الگوریتم این است که حتی با وجود اینکه اطلاعات به دست آمده ممکن است فقط اطلاعات تقریبی باشند (و نه قطعی) , میتوان میزان جذابیت راه حل زیرپایه را به راحتی مشخص کرد.بگذارید با در نظر گرفتن به عنوان میزان جذابیت راه حل زیرپایه ی i به توضیح میزان احتمال وقوع بپردازیم :
احتمال برای راه حل زیر پایه ی i که به راه حل اصلی الحاق میشود برابر است با نسبت میزان جذابیت تقسیم بر تمامی جذابیتهای راه حلهای زیر پایه ی دیگر :
برای اضافه کردن راه حلهای جدید به راه حل اصلی , زنبورها از نوعی انتخاب به نام Roulette Wheel Selection استفاده میکنند.
2.3.2: Bee"s Partial Solutions Coparison Mechanism
در توصیف مکانیزم مقایسه ی راه حلهای زیر پایه ی زنبور , ما موضوع "بدی راه حل زیرپایه" را معرفی میکنیم که برابر است با :
کمیتهای بالا به صورت زیر تعریف میشوند :
: بدی راه حل زیرپایه به وسیله ی k امین زنبور
: مقادیر تابع مفعولی از راه حل زیرپایه ایی که به وسیله ی ن امین زنبور کشف شده
: مقادیر تابع مفعولی از بهترین راه حل زیرپایه ی کشف شده از ابتدای روند جستجو تاکنون
: مقادیر تابع مفعولی از بدترین راه حل زیرپایه ی کشف شده از ابتدای روند جستجو تاکنون
الگوریتم منطق تقریبی برای تعیین بدی راه حل زیرپایه از قوانینی به شکل زیر تشکیل شده است :
اگر راه حل کشف شده بد بود
آنگاه وفاداری کم خواهد شد.
زنبورها از منطق تقریبی و مقایسه ی راه حلهای زیرپایه ی کشف شده شان با بهترین راه حل زیرپایه , و مقایسه ی راه حلهای زیرپایه کشف شده با بدترین راه حلها از آغاز روند جستجو استفاده میکند.
در این روش حقایق تاریخی که بوسیله ی تمامی اعضای کلونی زنبور بوجود آمده اند تاثیر قابل توجهی بر راههای آینده ی جستجو دارند.
2.3.3 : Bee"s Decision About Recruiting The Nestmates
از زمان شروع زندگی زنبورها و یا بهتر از بگوییم از زمان شروع زندگی حشرات اجتماعی , احتمال رخدادی است که در آن زنبور به پرواز در طول همان مسیر بدون گرفتن همراه ادامه دهد. احتمال بسیار کمی است ( <<1).
زنبورها تا محل رقص پواز میکنند و با احتمالی برابر با میرقصند.این نوع ارتباط بین زنبورها منجر به ساخته شدن فاکتوری به نام "هوش جمعی" میکند.
در اینحالت هنگامی که زنبور تصمیم میگیرد که همان مسیر را پرواز نکند , آن زنبور به سالن رقص رفته و از دیگر زنبورها پیروی خواهد کرد.
2.3.4 : Calculating The Number Of Bees Changing The Path
هر راه حل زیرپایه که در ناحیه ی رقص اعلان شده , دو ویژگی اصلی داشته است :
الف) مقادیر تابع مفعولی
ب) تعداد زنبورهایی که آن راه حل زیرپایه را اعلان کرده اند
این تعداد یک تعیین کننده ی خوب برای دانش دسته جمعی زنبورهاست.این فرایند نشان میدهد که چگونه کلونی زنبوری راه حل زیرپایه ی خاصی را در نظر میگیرد.
الگوریتم منطق تقریبی برای معین کردن جذابیت راه حل زیرپایه ی اعلان شده از قوانین زیر تشکیل شده است :
اگر طول راه اعلان شده کوتاه باشد و تعداد زنبورهای اعلان کننده کم باشد
آنگاه جذابیت راه حل زیرپایه متوسط است.
جذابیت محاسبه شده ی راه در این روش میتواند مقادیری بین 0 و 1 را اختیار کند.هر چقدر مقدار محاسبه زیادتر باشد , راه حل اعلان شده جذابیت بیشتری دارد.زنبورها کم و بیش به راه اولیه و قدیمی خود وفادارند , همزمان راه های اعلان شده ی جدید جذابیت کم و بیشی برای آنها خواهد داشت.
بعنوان مثال بیایید دو راه فرضی را و بنامیم.ما با تعداد زنبورهایی را که راه را ترک کرده اند و به جفتهایی ملحق شده اند که در طول راه پرواز میکنند , را مشخص میکنیم.
الگوریتم منطق تقریبی برای محاسبه ی تعداد زنبورهای جابجا شده شامل قوانینی به فرم زیر است :
اگر وفاداری زنبورها به راه پایین باشد و جذابیت راه بالا باشد
آنگاه تعداد زنبورهای جابجا شده از راه به راه بعدی بالا است.
در این روش تعداد زنبورهایی که در طول یک مسیر خاص پرواز میکنند , قبل از رفت بعدی تغییر داده شده.با استفاده از دانش اجتماعی و به اشتراک گذاری اطلاعات , زنبورها بر مسیرهای تضمین شده ی جستجو تمرکز میکنند , و مسیرهای کمتر تضمین شده را کم کم ترک میکنند.
4 : Case Study : The Ride-Matching Problem
شبکه های راه شهری در بیشتر کشورها به طرز شدیدی متراکم شده و در نتیجه زمان سفر درون شهری زیاد شده , تعداد توقفها افزایش یافته , وقفه های پیش بینی نشده , هزینه ی سفر درون شهری , مزاحمت برای رانندگان و مسافران و نیز آلودگی هوا , سطح صدای ناهنجار و تعداد تصادفات ناشی از ترافیک افزایش یافته است.
افزایش ظرفیت شبکه ی ترافیکی به وسیله ی ساختمانها و جاده های بیشتر در حالیمه هزینه های زیادی دارد , آسیبهای محیطی زیادی نیز دارد.استفاده ی موثرتر از منابع موجود برای حمایت از رشد تقاضای سفر ضروری است.
RideSharing یکی از تکنیکهای شناخته شده ی مدیریت رشد سفر (TDM) است که توصیه به شریک شدن دو یا چند نفر (با دو یا چند مبدا و مقصد) در یک وسیله ی نقلیه میکند.تمام رانندگانی که در RideSharing شرکت کردند به اپراتور اطلاعات زیر را در مورد تکنیک سفر اشاره شده , ارائه دادند :
الف) ظرفیت وسیله ی نقلیه (دو , سه و یا چهار نفر).
ب) روزهایی از هفته که هر فرد برای شرکت در RS حاضر است.
ج) مبدا سفر برای هر روز هفته.
د) مسافت سفر برای هر روز هفته.
ه)مقصد مورد نظر و/یا زمان رسیدن برای هر روز هفته
مسئله ی RS که در این مقاله به آن اشاره شده میتواند به روش زیر تعریف شود :
مسیریابی و زمان بندی وسایل نقلیه و مسافران برای تمامی هفته در "بهترین روش ممکن".
موارد زیر توابع پتانسیل مفعولی هستند :
الف) کمینه کردن کل مسافتی که توسط تمامی اعضای شرکت کننده پیموده میشود
ب) کمینه کردن وقفه ی کل
ج) برابر کردن نسبی بهره برداری از وسایل نقلیه
ما وقتی از مسئله ی بهینه سازی ترکیبی معین استفاده میکنیم که مقصد در نظر گرفته شده یا زمان رسیدن هر دو ثابت هستند (برای مثال "من میخواهم راس ساعت 8 صبح سوار شوم") , به بیان دیگر در بسیاری از حالتهای زندگی واقعی مقصد در نظر گرفته شده و/یا زمان رسیدن , از منطق فازی طبعیت میکند (برای مثال "من میخواهم حدود ساعت 8 صبح سوار شوم") , در اینحالت با مسئله ی RS باید به عنوان مسئله ی بهینه سازی ترکیبی *دارای عدم قطعیت* رفتار کرد.
3.1 : Solving The Ride-Matching Problem By The Fuzzy Bee System
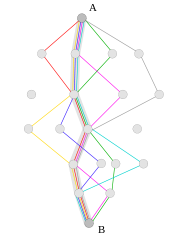
بیایید هر مسافری که در RS شرکت کرده است را بعنوان یک گره در نظر بگیریم (شکل 2).ما مسئله مان را به مراحلی تجزیه میکنیم.اولین سرنشین ماشین (راننده) مرحله ی اول معرفی میشود , دومین مسافری که به RS ملحق میشود (مرحله ی دوم) و...
در طی رفت زنبور تعداد معینی از گره ها را بازدید خواهد کرد , یک راه حل زیر پایه ایجاد میکند و پس از آن به کندو (یعنی گره ی O) برمیگردد.
در کندو زنبور در روند تصمیم گیری شرکت خواهد کرد.زنبورها تمام راه حلهای زیر پایه ی تولید شده را مقایسه میکنند.بر مبنای کیفیت راه حلهای زیرپایه ی تولید شده , هر زنبور تصمیم میگیرد که آیا مسیر تولید شده را ترک ند و زنبور سرگردان شود , یا به پرواز در طول مسیر کشف شده بدون گرفتن همراه ادامه دهد , یا برقصد و بدینگونه همراهی بگیرد قبل از آنکه به مسیر کشف شده بازگردد.
بسته به کیفیت راه حل زیر پایه ی تولید شده , هر زنبور سطح معینی از وفاداری را به راه قبلی کشف شده دارد.بعنوان مثال زنبورهای B1 و B2 و B3 در فرایند تصمیم گیری شرکت میکنند.پس از مقایسه ی تمام راه حلهای زیرپایه ی تولید شده , زنبور B1 تصمیم میگیرد راه فعلی را ترک کرده و به زنبور B2 ملحق شود.
زنبورهای B1 و B2 با هم در طول مسیری که به وسیله ی زنبور B2 تولید شده , پرواز میکنند.
هنگامی که به انتهای مسیر رسیدند آنها آزاد هستند تا تصمیمی فردی درباره ی گره ی بعدی که باید بازدید شود بگیرند.
زنبور B3 به پرواز در طول مسیر بدون گرفتن همراه ادامه میدهد(شکل 3).در این روش زنبورها دوباره عمل رفت را انجام میدهند.در طی دومین رفت زنبورها تعداد کمی گره ی بیشتر (نسبت به اولین بار) را ملاقات میکنند , راه حلهای زیرپایه ی تولید شده ی قبلی را توسعه میدهند و پس از آن دوباره عمل برگشت را اجرا میکنند و به کندو (گره ی O) بازمیگردند.
در کندو دوباره زنبورها در فرایند تصمیم گیری شرکت میکنند , تصمیم میگیرند , سومین رفت را اجرا میکنند و ...
تکرار هنگامی تمام میشود که زنبورها تمامی گره ها را بازدید کرده باشند.هنگام انتخاب گره ی بعدی که باید در رفت بعدی بازدید شود , زنبور گره ی خاصی را بعنوان "کمتر جذاب" , "جذاب" و "خیلی جذاب" در نظر میگیرد که وابسته به نزدیکی مکانی یا زمانی بین دو درخواست از دو مسافر است.
ما این نزدیکی ها را "فاصله ی مکانی در مبدا" , "فاصله ی مکانی در مسافت" و "فاصله ی زمانی در ورود به مقصد" مینامیم.
ما در نظر میگیریم که زنبور مصنوعی میتواند فاصله ی خاصی بین دو گره را با عنوانهای "کوتاه" , "متوسط" و "طولانی" شناسانی کند.
الگوریتم منطق تقریبی جذابیت گره را با قوانین زیر تعیین میکند :
اگر فاصله ی مکانی در مبدا کوتاه باشد و فاصله ی مکانی در مسافت کوتاه باشد و فاصله ی زمانی ورود کوتاه باشد
آنگاه جذابیت گره بالا است.
بدی راه (که در دومین معادله تعریف شد) در ارتباط با الگوریتم منطق تقریبی برای تعیین وفاداری زنبور به راه کشف شده استفاده میشود.الگوریتم منطق تقریبی برای تعیین جذابیت مسیر پیشنهاد شده از قوانین زیر تبعیت میکند :
اگر طول مسیر پیشنهادی کوتاه باشد و تعداد زنبورهایی که آن راه را پیشنهاد داده اند کم باشد
آنگاه جذابیت آن راه متوسط است.
3.2 : Numerical Experiment
ما مدل پیشنهادی را برای RS شهر Trani (شهر کوچک و زیبایی در جنوب ایتالیا) تا شهر Bari (مرکز منطقه ی Puglia) امتحان کردیم.ما اطلاعات مربوط به 97 مسافر که خواستار شرکت در پروژه ی RideSharing بودند را جمع آوری کرده و برای سادگی مسئله ظرفیت هر اتومبیل را چهار نفر در نظر گرفیم.در اینحالت الگوریتم 24*4 = 96 نفر از 97 نفر را برای ساختن بهترین راه کنار میگذارد.ما از کندویی با 15 زنبور , که سریعا (و یکبار) کندو را ترک میکنند استفاده کردیم.زنبورها فقط 6 مسیر غذایابی را پیدا کردند , و دیگر مسیرها رها شدند.
برای دیدن الگوریتم اینجا کلیک کنید
نوشته شده توسط لادن در چهارشنبه 90/2/7 و ساعت 2:37 عصر | نظرات دیگران()بهینهسازی گروه مورچهها یا ACO یک الگوریتم مناسب یافتن راهحلهای تقریبی برای مسائل بهینهسازی ترکیبیاتی است. در این روش، مورچههای مصنوعی بهوسیله حرکت بر روی نمودار مساله و با باقی گذاشتن نشانههایی بر روی نمودار، همچون مورچههای واقعی که در مسیر حرکت خود نشانههای باقی میگذارند، باعث میشوند که مورچههای مصنوعی بعدی بتوانند راهحلهای بهتری را برای مساله فراهم نمایند. همچنین در این روش میتوان توسط مسائل محاسباتی-عددی بر مبنای علم احتمالات بهترین مسیر را در یک نمودار یافت.

این روش که از رفتار مورچهها در یافتن مسیر بین محل لانه و غذا الهام گرفته شده؛ اولین بار در 1992 توسط مارکو دوریگو (Marco Dorigo) در پایان نامه دکترایش مطرح شد.
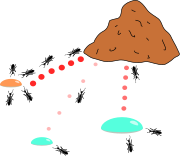
در دنیای واقعی مورچهها ابتدا به طور تصادفی به این سو و آن سو میروند تا غذا بیابند. سپس به لانه بر میگردند و ردّی از فرومون (Pheromone) به جا می گذارند. چنین ردهایی پس از باران به رنگ سفید در میآیند و قابل رویت اند. مورچههای دیگر وقتی این مسیر را مییابند، گاه پرسه زدن را رها کرده و آن را دنبال میکنند. سپس اگر به غذا برسند به خانه بر میگردند و رد دیگری از خود در کنار رد قبل می گذارند؛ و به عبارتی مسیر قبل را تقویت میکنند. فرومون به مرور تبخیر میشود که از سه جهت مفید است:
لذا وقتی یک مورچه مسیر کوتاهی (خوبی) را از خانه تا غذا بیابد بقیه مورچهها به احتمال زیادی همان مسیر را دنبال میکنند و با تقویت مداوم آن مسیر و تبخیر ردهای دیگر، به مرور همه مورچهها هم مسیر میشوند. هدف الگوریتم مورچهها تقلید این رفتار توسط مورچههایی مصنوعی ست که روی نمودار در حال حرکت اند. مساله یافتن کوتاهترین مسیر است و حلالش این مورچههای مصنوعی اند.
از کابردهای این الگوریتم، رسیدن به راه حل تقریباً بهینه در مسئله فروشنده دورهگرد است. به طوری که انواع الگوریتم مورچهها برای حل این مساله تهیه شده. زیرا این روش عددی نسبت به روشهای تحلیلی و genetic در مواردی که نمودار مدام با زمان تغییر کند یک مزیت دارد؛ و آن این که الگوریتمی ست با قابلیت تکرار. و لذا با گذر زمان میتواند جواب را به طور زنده تغییر دهد. که این خاصیت در روتینگ شبکههای کامپیوتری و سامانه حمل و نقل شهری مهم است.

پروسه پیدا کردن کوتاهترین مسیر توسط مورچه ها، ویژگیهای بسیار جالبی دارد، اول از همه قابلیت تعمیم زیاد و خود- سازمانده بودن آن است. در ضمن هیچ مکانیزم کنترل مرکزی ای وجود ندارد. ویژگی دوم قدرت زیاد آن است. سیستم شامل تعداد زیادی از عواملی است که به تنهایی بی اهمیت هستند بنابراین حتی تلفات یک عامل مهم، تاثیر زیادی روی کارآیی سیستم ندارد. سومین ویژگی این است که، پروسه یک فرآیند تطبیقی است. از آنجا که رفتار هیچ کدام از مورچهها معین نیست و تعدادی از مورچهها همچنان مسیر طولانی تر را انتخاب میکنند، سیستم می تواند خود را با تغییرات محیط منطبق کند و ویژگی آخر اینکه این پروسه قابل توسعه است و می تواند به اندازه دلخواه بزرگ شود. همین ویژگیها الهام بخش طراحی الگوریتم هایی شده اند که در مسائلی که نیازمند این ویژگیها هستند کاربرد دارند.اولین الگوریتمی که بر این اساس معرفی شد، الگوریتم ABC بود. چند نمونه دیگر از این الگوریتمها عبارتند از: AntNet،ARA،PERA،AntHocNet
نوشته شده توسط لادن در سه شنبه 90/2/6 و ساعت 8:21 صبح | نظرات دیگران()هوش ازدحامی (Swarm Intelligence) نوعی روش هوش مصنوعی است که مبتنی بر رفتارهای جمعی در سامانههای نامتمرکز و خودسامانده بنیان شده است. این سامانهها معمولاً از جمعیتی از کنشگران ساده تشکیل شده است که بطور محلی با یکدیگر و با محیط خود در تعامل هستند. با وجود اینکه معمولاً هیچ کنترل تمرکزیافتهای، چگونگی رفتار کنشگران را به آنها تحمیل نمیکند، تعاملات محلی آنها به پیدایش رفتاری عمومی میانجامد. مثالهایی از چنین سیستمهای را میتوان در طبیعت مشاهده کرد؛ گروههای مورچهها، دسته پرندگان، گلههای حیوانات، تجمعات باکتریها و دستههای ماهیها.
روباتیک ازدحامی، کاربردی از اصول هوش مصنوعی ازدحامی در تعداد زیادی از روباتهای ارزان قیمت است.
از موارد روشهای فرااکتشافی میتوان به موارد زیر اشاره کرد
دو روش اول موفقترین روشهای هوش مصنوعی ازدحامی که تاکنون اند.
بهینهسازی کلونی مورچه(Ant Colony Optimization)یکی از زیر مجموعههای هوش جمعی یا ازدحامی است که در آن از رفتار مورچههای واقعی برای یافتن کوناهترین مسیر بین لانه و منبع غذایی الگوبرداری شده است. هر مورچه برای یافتن غذا در اطراف لانه به صورت تصادفی حرکت و در طی مسیر با استفاده از ماده شیمیایی به نام فرومن، از خود ردی بر جای میگذارد.هر چه تعداد مورچههای عبور کرده از یک مسیر بیشتر باشد، میزان فرومن ذخیره شده روی آن مسیر نیز افزایش مییابد. سایر مورچهها نیز برای انتخاب مسیر حرکت، به میزان فرومن آن توجه و به احتمال زیاد مسیری را که دارای بیشترین فرومن است انتخاب میکنند. به این ترتیب حلقه بازخور مثبت ایجاد میگردد. مسیر هرچه کوتاهتر باشد، زمان رفت و برگشت کاهش و مورچه بیشتری در یک زمان مشخص از آن عبور میکند. در نتیجه ذخیره فرومن آن افزایش مییابد. لازم به ذکر است که انتخاب مسیر دارای بیشترین فرومن، قطعی نیست و احتمالی است. به همین دلیل امکان یافتن بهترین جواب وجود دارد. روش ACO، نوعی روش فرااکتشافی است که برای یافتن راهحلهای تقریبی برای مسائل بهینهسازی ترکیبیاتی مناسب است. روش ACO، مورچههای مصنوعی بهوسیله حرکت بر روی گرافِ مساله و با باقی گذاشتن نشانههایی بر روی گراف، همچون مورچههای واقعی که در مسیر حرکت خود نشانههای باقی میگذارند، باعث میشوند که مورچههای مصنوعی بعدی بتوانند راهحلهای بهتری را برای مساله فراهم نمایند.
روش PSO یک روش سراسری کمینهسازی است که با استفاده از آن میتوان با مسائلی که جواب آنها یک نقطه یا سطح در فضای n بعدی میباشد، برخورد نمود. در اینچنین فضایی، فرضیاتی مطرح میشود و یک سرعت ابتدایی به آنها اختصاص داده میشود، همچنین کانالهای ارتباطی بین ذرات درنظر گرفته میشود. سپس این ذرات در فضای پاسخ حرکت میکنند، و نتایج حاصله بر مبنای یک «ملاک شایستگی» پس از هر بازه زمانی محاسبه میشود. با گذشت زمان، ذرات به سمت ذراتی که دارای ملاک شایستگی بالاتری هستند و در گروه ارتباطی یکسانی قرار دارند، شتاب میگیرند. مزیت اصلی این روش بر استراتژیهای کمینهسازی دیگر این است که، تعداد فراوان ذرات ازدحام کننده، باعث انعطاف روش در برابر مشکل پاسخ کمینه? محلی میگردد.
همگونیهایی بین مسائل متفاوت در حوزه? فناوری اطلاعات و رفتارهای حشرات اجتماعی وجود دارد :
مراحل طراحی یک سامانه با کاربردهای فناوری اطلاعات بر مبنای هوش مصنوعی ازدحامی فرآیندی سه مرحلهای است :
نوشته شده توسط لادن در دوشنبه 90/2/5 و ساعت 2:50 عصر | نظرات دیگران()دادهکاوی پایگاهها و مجموعههای حجیم دادهها را در پی کشف واستخراج دانش مورد تحلیل و کند و کاوهای ماشینی (و نیمهماشینی) قرار میدهد. این گونه مطالعات و کاوشها را به واقع میتوان همان امتداد و استمرار دانش کهن و همه جا گیر آمار دانست. تفاوت عمده در مقیاس، وسعت و گوناگونی زمینهها و کاربردها، و نیز ابعاد و اندازههای دادههای امروزین است که شیوههای ماشینی مربوط به یادگیری، مدلسازی، و تعلّم را طلب مینماید.
اصلاح Data Mining همان طور که از ترجمه آن به معنی داده کاوی مشخص میشود به مفهوم استخراج اطلاعات نهان و یا الگوها وروابط مشخص در حجم زیادی از دادهها به یک یا چند بانک اطلاعاتی بزرگ است.
بسیاری از شرکتها و موسسات دارای حجم انبوهی از اطلاعات هستند. تکنیکهای دادهکاوی به طور تاریخی به گونهای گسترش یافتهاند که به سادگی میتوان آنها را با ابزارهای نرمافزاری امروزی و موجود در این موسسات تطبیق داده و از اطلاعات جمع آوری شده فعلی بهترین بهره را برد. در صورتی که سیستمهای Data Mining بر روی سکوهای Client/Server قوی نصب شده باشد و دسترسی به بانکهای اطلاعاتی بزرگ فراهم باشد، به کمک چنین سیستمهایی میتوان به سوالاتی از قبیل :کدامیک از مشتریان ممکن است خریدار کدامیک از محصولات آینده شرکت باشد «چراًدر کدام مقطع زمانی»و بسیاری از موارد مشابه پاسخ داد.
یکی از ویژگیهای کلیدی در بسیاری از ابتکارات مربوط به تامین امنیت ملی داده کاوی است. داده کاوی که به عنوان ابزاری برای کشف جرایم، ارزیابی میزان ریسک و فروش محصولات به کار میرود، در بر گیرنده ابزارهای تجزیه و تحلیل اطلاعات به منظور کشف الگوهای معتبر و ناشناخته در بین انبوهی از داده هاست.داده کاوی غالبا در زمینه تامین امنیت ملی به منزله ابزاری برای شناسایی فعالیتهای افراد خرابکار شامل جابه جایی پول و ارتباطات بین آنها و همچنین شناسایی و ردگیری خود آنها با برسی سوابق مربوط به مهاجرت و مسافرت هاست. داده کاوی پیشرفت قابل ملاحظهای را در نوع ابزارهای تحلیل موجود نشان میدهد اما محدودیتهایی نیز دارد. یکی از این محدودیتها این است که با وجود اینکه به آشکارسازی الگوها و روابط کمک میکند اما اطلاعاتی را در باره ارزش یا میزان اهمیت آنها به دست نمیدهد. دومین محدودیت آن این است که با وجود توانایی شناسایی روابط بین رفتارها و یا متغیرها لزوما قادر به کشف روابط علت و معلولی نیست. موفقیت داده کاوی را نباید در گرو بهره گیری از کارشناسان فنی و تحلیل گران کار آزمودهای است که از توانایی کافی برای طبقه بندی تحلیلها و تغییر آنها برخور دار هستند. بهره برداری از داده کاوی رو بر دو بخش دولتی و خصوصی رو به گسترش است. صنایعی چون بانکداری، بیمه، بهداشت و بازار یابی آنرا عموما برای کاهش هزینهها، ارتقاء کیفی پژوهشها و بالاتر بردن میزان فروش به کار میبرند. کاربرد اصلی داده کاوی در بخش دولتی به عنوان ابزاری برای تشخیص جرایم بودهاست اما امروزه دامنه بهره برداری از آن گسترش روز افزونی یافته و سنجش و بهینه سازی برنامهها ربا نیز در بر میگیرد. برسی برخی از برنامههای کاربردی مربوط به داده کاوی که برای تامین امنیت ملی به کار میروند نشان دهنده رشد قابل ملاحظهای در رابطه با کمیت و دامنه دادههایی است که باید تجزیه و تحلیل شوند. تواناییهای فنی در داده کاوی از اهمیت ویژهای برخوردار اند اما عوامل دیگری نیز مانند چگونگی پیاده سازی و نظارت ممکن است نتیجه کار را تحت تاپیر قرار دهند. یکی از این عوامل کیفیت داده هاست که بر میزان دقت و کامل بودن آن دلالت دارد. عامل دوم میزان سازگاری نرمافزار داده کاوی با بانکهای اطلاعاتی است که از سوی شرکتهای متفاوتی عرضه میشوند عامل سومی که باید به آن اشاره کرد به بیراهه رفتن داده کاوی و بهره برداری از دادهها به منظوری است که در ابتدا با این نیت گرد آوری نشدهاند حفظ حریم خصوصی افراد عامل دیگری است که باید به آن توجه داشت اصولا به پرسشهای زیر در زمینه داده کاوی باید پاسخ داده شود:
کاوش در دادهها بخشی بزرگ از سامانههای هوشمند است. سامانههای هوشمند زیر شاخهایست بزرگ و پرکاربرد از زمینه علمی جدید و پهناور یادگیری ماشینی که خود زمینهایست در هوش مصنوعی.
فرایند گروه گروه کردن مجموعهای از اشیاء فیزیکی یا مجرد به صورت طبقههایی از اشیاء مشابه هم را خوشهبندی مینامیم.
با توجه به اندازههای گوناگون (و در اغلب کاربردها بسیار بزرگ و پیچیده) مجموعههای دادهها مقیاسپذیری الگوریتمهای به کار رفته معیاری مهم در مفاهیم مربوط به کاوش در دادهها است.
کاوشهای ماشینی در متون حالتی خاص از زمینه عمومیتر کاوش در دادهها بوده، و به آن دسته از کاوشها اطلاق میشود که در آنها دادههای مورد مطالعه از جنس متون نوشته شده به زبانهای طبیعی انسانی باشد.
داده کاوی به بهره گیری از ابزارهای تجزیه و تحلیل دادهها به منظور کشف الگوها و روابط معتبری که تا کنون ناشناخته بودهاند اطلاق میشود. این ابزارها ممکن است مدلهای آماری الگوریتمهای ریاضی و روشهای یاد گیرنده (Machine Laming Method) باشند که کار این خود را به صورت خودکار و بر اساس تجربهای که بر اساس تجربهای که از طریق شبکههای عصبی (Networks Several) یا درختهای تصمیم گیری (Decision Tree) به دست میآورند بهبود میبخشد. داده کاوی منحصر به گردآوری و مدریت دادهها نبوده و تجزیه و تحلیل اطلاعات و پیش بنی را نیز شامل میشود برنامههای کاربردی که با برسی فایلهای متن یا چند رسانهای به کاوش دادههای پردازنده پارامترهای گوناگونی را در نظر میگیرد که عبارت اند از: *رابطه (Association): الگوهایی که بر اساس آن یک رویداد به دیگری مربوط میشود مثلا خرید قلم به خرید کاغذ.
برنامههای کاربردی که در زمینه تجزیه و تحلیل اطلاعات به کار میروند از امکاناتی چون پرس و جوی ساخت یافته (Structured query) که در بسیاری از بانکهای اطلاعاتی یافت میشود و در ابزارهای تجزیه و تحلیل آماری برخوردار اند اما برنامههای مربوط به داده کاوی در عین برخورداری از این قابلیتها از نظر نوع با آنها تفاوت دارند. بسیاری از ابزارهای ساده برای تجزیه و تحلیل دادهها روشی بر پایه راستی آزمایی (verifi action)را به کار میبرند که در آن فریضهای بسط داده شده آنگاه دادهها برای تایید یا رد آن بررسی میشوند. به طور مثال ممکن است این نظریه مطرح شود که فردی که یک چکش خریده حتماً یک بسته میخ هم خواهد خرید. کارایی این روش به میزان خلاقیت کاربر برای اریه فریضههای متنوع و همچنین ساختار برنامه بکار رفته بستگی دارد. در مقابل در داده کاوی روشهایی برای کشف روابط بکار برده میشوند و به کمک الگوریتمهایی روابط چند بعدی بین دادهها تشخیص داده شده و آنهایی که یکتا (unique) یا رایج هستند شناسایی میشوند. به طور مثال در یک فروشگاه سختافزار ممکن است بین خرید ابزار توسط مشتریان با تملک خانه شخصی یا نوع خودرو، سن، شغل، میزان درآمد یا فاصله محل اقامت آنها با فروشگاه رابطهای برقرار شود.
در نتیجه قابلیتهای پیچیده اش برای موفقیت در تمرین داده کاوی دو مقدمه مهم است یکی فرمول واضحی از مشکل که قابل حل باشد و دیگری دسترسی به داده متناسب. بعضی از ناظران داده کاوی را مرحلهای در روند کشف د انش در پایگاه دادهها میدانند (KDD). مراحل دیگری در روند KDD به صورت تساعدی شامل، پاکسازی داده، انتخاب داده انتقال داده، داده کاوی، الگوی ارزیابی، و عرضه دانش میباشد. بسیاری از پیشرفتها در تکنولوژی و فرآیندهای تجاری بر رشد علاقه مندی به داده کاوی در بخشهای خصوصی و عمومی سهمی داشتهاند. بعضی از این تغییرات شامل:
علاوه بر پیشرفت ابزارهای مدیریت داده، افزایش قابلیت دسترسی به داده و کاهش نرخ نگهداری داده نقش ایفا میکند. در طول چند سال کذشته افزایش سریع جمع آوری و نگه داری حجم اطلاعات وجود داشتهاست. با پیشنهادهای برخی از ناظران مبنی بر آنکه کمیت دادههای دنیا به طور تخمینی هر ساله دوبرابر میگردد. در همین زمان هزینه ذخیره سازی دادهها بطور قابل توجهی از دلار برای هر مگابایت به پنی برای مگابایت کاهش پیدا کردهاست. مطابقا قدرت محاسبهها در هر 18– 24ماه به دوبرابر ارتقاء پیدا کردهاست این در حالی است که هزینه قدرت محاسبه رو به کاهش است. داده کاو به طور معمول در دو حوزه خصوصی و عمومی افزایش پیدا کردهاست. سازمانها داده کاوی را به عنوان ابزاری برای بازدید اطلاعات مشتریان کاهش تقلب و اتلاف و کمک به تحقیقات پزشکی استفاده میکنند. با اینهمه ازدیاد داده کاوی به طبع بعضی از پیاده سازی و پیامد اشتباه را هم دارد.اینها شامل نگرانیهایی در مورد کیفیت دادهای که تحلیل میگردد، توانایی کار گروهی پایگاههای داده و نرمافزارها بین ارگانها و تخطیهای بالقوه به حریم شخصی میباشد.همچنین ملاحظاتی در مورد محدودیتهایی در داده کاوی در ارگانها که کارشان تاثیر بر امنیت دارد، نادیده گرفته میشود.
در حالیکه محصولات داده کاوی ابزارهای قدرتمندی میباشند، اما در نوع کاربردی کافی نیستند.برای کسب موفقیت، داده کاوی نیازمند تحلیل گران حرفهای و متخصصان ماهری میباشد که بتوانند ترکیب خروجی بوجود آمده را تحلیل و تفسیر نمایند.در نتیجه محدودیتهای داده کاوی مربوط به داده اولیه یا افراد است تا اینکه مربوط به تکنولوژی باشد.
اگرچه داده کاوی به الگوهای مشخص و روابط آنها کمک میکند، اما برای کاربر اهمیت و ارزش این الگوها را بیان نمیکند.تصمیماتی از این قبیل بر عهده خود کاربر است.برای نمونه در ارزیابی صحت داده کاوی، برنامه کاربردی در تشخیص مظنونان تروریست طراحی شده که ممکن است این مدل به کمک اطلاعات موجود در مورد تروریستهای شناخته شده، آزمایش شود.با اینهمه در حالیکه ممکن است اطلاعات شخص بطور معین دوباره تصدیق گردد، که این مورد به این منظور نیست که برنامه مظنونی را که رفتارش به طور خاص از مدل اصلی منحرف شده را تشخیص بدهد.
تشخیص رابطه بین رفتارها و یا متغیرها یکی دیگر از محدودیتهای داده کاوی میباشد که لزوماًروابط اتفاقی را تشخیص نمیدهد.برای مثال برنامههای کاربردی ممکن است الگوهای رفتاری را مشخص کند، مثل تمایل به خرید بلیط هواپیما درست قبل از حرکت که این موضوع به مشخصات درآمد، سطح تحصیلی و استفاده از اینترنت بستگی دارد.در حقیقت رفتارهای شخصی شامل شغل(نیاز به سفر در زمانی محدود)وضع خانوادگی(نیاز به مراقبت پزشکی برای مریض)یا تفریح (سود بردن از تخفیف دقایق پایانی برای دیدن مکانهای جدید) ممکن است بر روی متغیرهای اضافه تاثیر بگذارد.
Two Crows Corporation, Introduction to Data Mining and Knowledge Discovery, Third Edition (Potomac, MD: Two Crows Corporation, 1999); Pieter Adriaans and Dolf Zantinge, Data Mining New York: Addison Wesley, 1996
John Makulowich, “Government Data Mining Systems Defy Definition,” Washington Technology, 22 February 1999, [http://www.washingtontechnology.com/news/13_22/tech_ features/393-3.html
Jiawei Han and Micheline Kamber, Data Mining: Concepts and Techniques (New York: Morgan Kaufmann Publishers, 2001), p. 7
Pieter Adriaans and Dolf Zantinge, Data Mining (New York: Addison Wesley, 1996), pp. 5-6
Two Crows Corporation, Introduction to Data Mining and Knowledge Discovery, Third Edition (Potomac, MD: Two Crows Corporation, 1999), p.4 .
نوشته شده توسط لادن در پنج شنبه 90/2/1 و ساعت 9:43 صبح | نظرات دیگران()





.jpg)


