وبلاگ چت روم کامپیوتر و شبکه در سایت الفور

سامانههای خِبره یا سیستمهای خِبره (Expert systems) به دستهای خاص از نرمافزارهای رایانهای اطلاق میشود که در راستای کمک به کاردانان و متخصّصان انسانی و یا جایگزینی جزئی آنان در زمینههای محدود تخصّصی تلاش دارند. اینگونه سامانهها، در واقع، نمونههای ابتدایی و سادهتری از فنآوری پیشرفتهتر سامانههای مبتنی بر دانش به حساب میآیند.
این سامانهها معمولاً اطلاعات را به شکل واقعیات[1] و قواعد[2] در دادگانی به نام پایگاه دانش به شکل ساختار مند ذخیره نموده، و سپس با استفاده از روشهایی خاص استنتاج از این دادهها نتایج مورد نیاز حاصل میشود.
سامانههای تجربی موجبات انجام امور و یا تسهیل در انجام آنها را در زمینههای متنوّعی همچون پزشکی، حسابداری، کنترل فرایندها، منابع انسانی، خدمات مالی، و GIS فراهم میآورند. در هر یک از این زمینهها می توان کارهایی از نوع راهنمایی، تحلیل، دستهبندی، مشاوره، طراحی، تشخیص، کاوش، پیش بینی، ایجاد مفاهیم، شناسایی، توجیه، یادگیری، مدیریت، کنترل، برنامهریزی، زمان بندی و آزمایش را با مددجویی از سیستمهای تجربی با سرعت و سهولت بیشتری به انجام رسانید. †
سیستمهای تجربی یا به عنوان جایگزین فرد متخصص یا به عنوان کمک به وی استفاده میشوند.
نظام های خبره این امکان را در اختیار می گذارد تا بتوان دانش موجود در سطح جامعه را به صورت گسترده تر و کم هزینه تری اشاعه داد . این موضوع یعنی اشاعه دانش برای عموم مردم یکی از بنیادی ترین و اصلی ترین وظایف و رسالتهای حوزه کتابداری است .
مثلا از طریق واسطهای هوشمند جست و جوی اطلاعات می توان مهارتهای جستجوی پیشرفته را که اغلب خاص متخصصان با تجربه است در میان طیف وسیعی از کاربران در دسترس قرار دهد . سرعت استدلال یا حل مسائل در نظام های خبره می تواند منجر به ارائه خدمات موثرتر و سریع تر در برخی فعالیتهای کتابداری شود و انعطاف پذیری بیشتری را در پاسخگویی به نیازهای مخاطبان به وجود آورد.
کاربرد نظام های خبره و هوشمند را در حوزه های نمایه سازی، چکیده نویسی، طراحی و تولید اصطلاحنامه ها، فهرست نویسی، بازیابی متن فارغ از منطق بولی، بازیابی متون مبتنی بر منطق بولی، تجزیه و تحلیل خودکار محتوا و ارائه دانش، مدیریت و دسترسی به محتوی پایگاه های رابطه ای، اسناد هوشمند، تجزیه و تحلیل پایگاه های اطلاعاتی دانسته اند.
تا ابتدای دهه 1980 (م) کار چندانی در زمینه ساخت و ایجاد سامانههای خِبره توسط پژوهش گران هوش مصنوعی صورت نگرفته بود. از آن زمان به بعد، کارهای زیادی در این راستا و در دو حوزه? متفاوت ولی مرتبط سامانههای کوچک خبره و نیز سامانههای بزرگ خبره انجام شده است.
هوش مصنوعی: هوش مصنوعی روشی است در جهت هوشمند کردن کامپیوتر تا قادر باشد در هر لحظه تصمیم گیری کرده و اقدام به بررسی یک مسئله نماید. هوش مصنوعی، کامپیوتر را قادر به تفکر میکند و روش آموختن انسان را تقلید می نماید. بنابراین اقدام به جذب اطلاعات جدید جهت بکارگیری مراحل بعدی می پردازد.
مغز انسان به بخش هایی تقسیم شده است که هر بخش وظیفه خاص خود را جدا از بقیه انجام می دهد. اختلال در کار یک بخش تاثیری در دیگر قسمتهای مغز نخواهد گذاشت. در برنامههای هوش مصنوعی نیز این مسئله رعایت میشود درحالی که در برنامههای غیر هوش مصنوعی مثل C یا Pascal تغییر در برنامه روی سایر قسمتهای برنامه و اطلاعات تاثیر دارد.
مباحث کاربردی و مهم در تحقق یک سیستم هوش مصنوعی :
1-سیستمهای خبره (Expert Systems)
2-شبکههای عصبی (Neural Network)
3- الگوریتمهای ژنتیک (Genetic Algorithms)
4- سیستمهای منطق فازی (Fuzzy Logic Systems)
سیستمهای خبره برنامه هایی هستند که رفتار یک انسان متخصص در یک زمینه بخصوص را تقلید می کنند. این برنامه از اطلاعاتی که استفاده کننده در آنها ذخیره میکند جهت اعلام یک عقیده در یک موضوع بخصوص استفاده می کند. از اینرو سیستمهای خبره تا هنگامی که بتوانند موضوعی را که با پاسخهای شما مطابقت داشته باشد بیابند به سوال کردن از شما ادامه می دهند. به منظور درک کردن آنچه یک سیستم متخصص انجام می دهد مکالمه زیر که بین یک متخصص در امور میوه و فرد دیگری که می خواهد از وی توصیه ای در این مورد دریافت کند را در نظر بگیرید:
- متخصص: آیا میوه سبز است؟
- استفاده کننده: خیر.
- متخصص: آیا میوه قرمز است؟
- استفاده کننده: بله.
- متخصص: آیا این میوه روی درخت رشد می کند؟
- استفاده کننده: خیر.
- متخصص: آیا این میوه روی یک بوته رشد می کند؟
- استفاده کننده: بله.
- متخصص: آیا این بوته تیغ دارد؟
- استفاده کننده: بله.
- متخصص: این میوه تمشک است!
هدف از طراحی یک سیستم متخصص کامپیوتری در امر میوه تولید این مکالمه است. در حالت عمومی تر سیستم متخصص سعی میکند که به استفاده کننده از خود در مورد موضوعی که از آن مطلع است راهنمایی دهد.
مزایای یک سیستم خبره چیست؟
میزان مطلوب بودن یک سیستم خبره اصولا به میزان قابلیت دسترسی به آن و میزان سهولت کار با آن بستگی دارد.
می توان مزایایی که یک سیستم خبره در برابر انسان خبره دارد را به این صورت نام برد:
مثال هایی از سیستمهای متخصص تجاری:
در اوایل دهه 80 سیستمهای متخصص به بازار عرضه شد که می توانستند مشورتهای مالیاتی، توصیههای بیمه ای و یا قانونی را به استفاده کنندگان خود ارائه دهند.
سیستمهای متخصص چگونه کار می کنند؟
هر سیستم متخصص از دو بخش تشکیل میشود:
- بانک اطلاعاتی
- تولید کننده مکالمه
منظور از بانک اطلاعاتی در اینجا مکانیسم نگهداری اطلاعات و قوانین ویژه ای در مورد یک موضوع بخصوص می باشد. با این توصیف دو اصطلاح زیر تعریف میشود:
- شیء (): منظور از شیء در اینجا نتیجه ای است که با توجه به قوانین مربوط به آن تعریف می گردد.
- شاخص (Attribute): منظور از شاخص یا «صفت» یک کیفیت ویژه است که با توجه به قوانینی که برای آن در نظر گرفته شده است به شما در تعریف شیء یاری می دهد.
بنابراین می توان بانک اطلاعاتی را بصورت لیستی از اشیاء که در آن قوانین و شاخصهای مربوط به هر شیء نیز ذکر شده است در نظر گرفته شود.
در سادهترین حالت(که در اکثر کاربردها نیز همین حالت بکار می رود) قانونی که به یک شاخص اعمال میشود این مطلب را بیان میکند که آیا شیء مورد نظر شاخص دارد یا ندارد؟
یک سیستم متخصص که انواع مختلف میوه را شناسایی میکند احتمالاً دارای بانک اطلاعاتی به صورت زیر خواهد بود:
شیء قانون شاخص
سیب دارد روی درخت رشد می کند.
دارد گرد است
دارد رنگ قرمز یا زرد است
ندارد در کویر رشد می کند
انگور ----- -------------------
بانک ساده شده بالا، تنها با استفاده از قانون <<دارد>>:
| شیء | شاخص هایی که دارد |
|---|---|
| سیب | رشد روی درخت |
| سیب | گرد بودن |
| سیب | رنگ قرمز یا زرد |
| سیب | رشد نکردن در کویر |
تولید کننده مکالمهآن بخش از سیستم متخصص است که سعی میکند از اطلاعاتی که شما ذخیره کرده اید جهت یافتن یک شیء منطبق با خواسته شما استفاده نماید.
دو نوع عمده از تولید کنندههای مکالمه وجود دارد:
برخی قوانین قطعی هستند. به عنوان مثال یک شیمیدان می تواند با قطعیت و یقین اعلام کند که اگر اتم مورد نظر دارای 2 الکترون باشد آنگاه این اتم به عنصر هلیم تعلق دارد. اکثر قوانین قطعی نیستند بلکه با یک درصد مشخص، احتمال وقوع آنها می رود. با این وجود در بسیاری از اینگونه موارد عامل عدم قطعیت از نظر آماری اهمیت چندانی ندارد و از این رو شما می توانید با این قوانین بصورت قوانین جبری برخورد کنید.
در رابطه با این دو گروه عمده(یعنی قطعی و عدم قطعی) سه روش اساسی برای ساخت «تولید کننده مکالمه» وجود دارد:
تفاوت بین این سه روش به شیوه ای که «تولید کننده مکالمه» توسط آن سعی میکند به هدف خود برسد، بستگی دارد.
 نوشته شده توسط لادن در جمعه 90/1/26 و ساعت 10:20 صبح | نظرات دیگران()
نوشته شده توسط لادن در جمعه 90/1/26 و ساعت 10:20 صبح | نظرات دیگران()اگر در یک شرکت یا سازمان کار می کنید که کامپیوترها بصورت شبکه به هم اتصال هستند حتی اگر در اینترنت نباشید مراقب رفتار خود باشید از طریق نرم افزارهای مختلف مثلا نرم افزار بنام winvnc مدیر شبکه میتواند کلیه کارهای شمارا روی مونیتور خود ببیند حتی به جای شما با کامپیوترتان کار کند بطور ساده بگویم هر کاری که شما با کامپیوتر انجام می د هید و روی مونیتور خود می بینید آن شخص همین تصاویر و اعمال را روی مونیتور خود می بیند حتی اگر به اینترنت وصل نباشید .بهتر است بدانید شبکه و اینترنت خیلی نا امن است
نوشته شده توسط علی در جمعه 90/1/26 و ساعت 9:50 صبح | نظرات دیگران()الگوریتم ژنتیک (Genetic Algorithm - GA) تکنیک جستجویی در علم رایانه برای یافتن راهحل تقریبی برای بهینهسازی و مسائل جستجو است. الگوریتم ژنتیک نوع خاصی از الگوریتمهای تکامل است که از تکنیکهای زیستشناسی فرگشتی مانند وراثت و جهش استفاده میکند.
در واقع الگوریتمهای ژنتیک از اصول انتخاب طبیعی داروین برای یافتن فرمول بهینه جهت پیشبینی یا تطبیق الگو استفاده میکنند.الگوریتمهای ژنتیک اغلب گزینه خوبی برای تکنیکهای پیشبینی بر مبنای رگرسیون هستند. مختصراً گفته میشود که الگوریتم ژنتیک (یا GA) یک تکنیک برنامهنویسی است که از تکامل ژنتیکی به عنوان یک الگوی حل مسئله استفاده میکند.مسئلهای که باید حل شود ورودی است و راهحلها طبق یک الگو کد گذاری میشوند که تابع fitness نام دارد هر راه حل کاندید را ارزیابی میکند که اکثر آنها به صورت تصادفی انتخاب میشوند.
کلاً این الگوریتمها از بخش های زیر تشکیل میشوند : تابع برازش - نمایش – انتخاب – تغییر
هنگامی که لغت تنازع بقا به کار میرود اغلب بار ارزشی منفی آن به ذهن میآید. شاید همزمان قانون جنگل به ذهن برسد و حکم بقای قویترها!
البته همیشه هم قویترینها برنده نبودهاند. مثلاً دایناسورها با وجود جثه عظیم و قویتر بودن در طی روندی کاملاً طبیعی بازیِ بقا و ادامه نسل را واگذار کردند در حالی که موجوداتی بسیار ضعیفتر از آنها حیات خویش را ادامه دادند. ظاهراً طبیعت، بهترینها را تنها بر اساس هیکل انتخاب نمیکند! در واقع درستتر آنست که بگوییم طبیعت مناسب ترینها (Fittest) را انتخاب میکند نه بهترینها.
قانون انتخاب طبیعی بدین صورت است که تنها گونههایی از یک جمعیت ادامه نسل میدهند که بهترین خصوصیات را داشته باشند و آنهایی که این خصوصیات را نداشته باشند به تدریج و در طی زمان از بین میروند.
مثلا فرض کنید گونه خاصی از افراد، هوش بیشتری از بقیه افرادِ یک جامعه یا کولونی دارند. در شرایط کاملاً طبیعی، این افراد پیشرفت بهتری خواهند کرد و رفاه نسبتاً بالاتری خواهند داشت و این رفاه، خود باعث طول عمر بیشتر و باروری بهتر خواهد بود (توجه کنید شرایط، طبیعیست نه در یک جامعه سطح بالا با ملاحظات امروزی؛ یعنی طول عمر بیشتر در این جامعه نمونه با زاد و ولد بیشتر همراه است). حال اگر این خصوصیت (هوش) ارثی باشد بالطبع در نسل بعدی همان جامعه تعداد افراد باهوش به دلیل زاد و ولد بیشترِ اینگونه افراد، بیشتر خواهد بود. اگر همین روند را ادامه دهید خواهید دید که در طی نسلهای متوالی دائماً جامعه نمونه ما باهوش و باهوشتر میشود. بدین ترتیب یک مکانیزم ساده طبیعی توانسته است در طی چند نسل عملاً افراد کم هوش را از جامعه حذف کند علاوه بر اینکه میزان هوش متوسط جامعه نیز دائماً در حال افزایش است.
بدین ترتیب میتوان دید که طبیعت با بهرهگیری از یک روش بسیار ساده (حذف تدریجی گونههای نامناسب و در عین حال تکثیر بالاتر گونههای بهینه)، توانسته است دائماً هر نسل را از لحاظ خصوصیات مختلف ارتقاء بخشد.
البته آنچه در بالا ذکر شد به تنهایی توصیف کننده آنچه واقعاً در قالب تکامل در طبیعت اتفاق میافتد نیست. بهینهسازی و تکامل تدریجی به خودی خود نمیتواند طبیعت را در دسترسی به بهترین نمونهها یاری دهد. اجازه دهید تا این مسأله را با یک مثال شرح دهیم:
پس از اختراع اتومبیل به تدریج و در طی سالها اتومبیلهای بهتری با سرعتهای بالاتر و قابلیتهای بیشتر نسبت به نمونههای اولیه تولید شدند. طبیعیست که این نمونههای متأخر حاصل تلاش مهندسان طراح جهت بهینهسازی طراحیهای قبلی بودهاند. اما دقت کنید که بهینهسازی یک اتومبیل، تنها یک "اتومبیل بهتر" را نتیجه میدهد.
اما آیا میتوان گفت اختراع هواپیما نتیجه همین تلاش بوده است؟ یا فرضاً میتوان گفت فضاپیماها حاصل بهینهسازی طرح اولیه هواپیماها بودهاند؟
پاسخ اینست که گرچه اختراع هواپیما قطعاً تحت تأثیر دستاورهای صنعت اتومبیل بوده است؛ اما بههیچ وجه نمیتوان گفت که هواپیما صرفاً حاصل بهینهسازی اتومبیل و یا فضاپیما حاصل بهینهسازی هواپیماست. در طبیعت هم عیناً همین روند حکمفرماست. گونههای متکاملتری وجود دارند که نمیتوان گفت صرفاً حاصل تکامل تدریجی گونه قبلی هستند.
در این میان آنچه شاید بتواند تا حدودی ما را در فهم این مسأله یاری کند مفهومیست به نام تصادف یا جهش.
به عبارتی طرح هواپیما نسبت به طرح اتومبیل یک جهش بود و نه یک حرکت تدریجی. در طبیعت نیز به همین گونهاست. در هر نسل جدید بعضی از خصوصیات به صورتی کاملاً تصادفی تغییر مییابند سپس بر اثر تکامل تدریجی که پیشتر توضیح دادیم در صورتی که این خصوصیت تصادفی شرایط طبیعت را ارضا کند حفظ میشود در غیر اینصورت به شکل اتوماتیک از چرخه طبیعت حذف میگردد.
در واقع میتوان تکامل طبیعی را به اینصورت خلاصه کرد: جستوجوی کورکورانه (تصادف یا Blind Search) + بقای قویتر.
حال ببینیم که رابطه تکامل طبیعی با روشهای هوش مصنوعی چیست. هدف اصلی روشهای هوشمندِ به کار گرفته شده در هوش مصنوعی، یافتن پاسخ بهینه مسائل مهندسی است. بعنوان مثال اینکه چگونه یک موتور را طراحی کنیم تا بهترین بازدهی را داشته باشد یا چگونه بازوهای یک ربات را متحرک کنیم تا کوتاهترین مسیر را تا مقصد طی کند (دقت کنید که در صورت وجود مانع یافتن کوتاهترین مسیر دیگر به سادگی کشیدن یک خط راست بین مبدأ و مقصد نیست) همگی مسائل بهینهسازی هستند.
روشهای کلاسیک ریاضیات دارای دو اشکال اساسی هستند. اغلب این روشها نقطه بهینه محلی (Local Optima) را بعنوان نقطه بهینه کلی در نظر میگیرند و نیز هر یک از این روشها تنها برای مسأله خاصی کاربرد دارند. این دو نکته را با مثالهای سادهای روشن میکنیم.

به شکل زیر توجه کنید. این منحنی دارای دو نقطه ماکزیمم میباشد. که یکی از آنها تنها ماکزیمم محلی است. حال اگر از روشهای بهینهسازی ریاضی استفاده کنیم مجبوریم تا در یک بازه بسیار کوچک مقدار ماکزیمم تابع را بیابیم. مثلاً از نقطه 1 شروع کنیم و تابع را ماکزیمم کنیم. بدیهی است اگر از نقطه 1 شروع کنیم تنها به مقدار ماکزیمم محلی دست خواهیم یافت و الگوریتم ما پس از آن متوقف خواهد شد. اما در روشهای هوشمند، به ویژه الگوریتم ژنتیک بدلیل خصلت تصادفی آنها حتی اگر هم از نقطه 1 شروع کنیم باز ممکن است در میان راه نقطه A به صورت تصادفی انتخاب شود که در این صورت ما شانس دستیابی به نقطه بهینه کلی (Global Optima) را خواهیم داشت.
در مورد نکته دوم باید بگوییم که روشهای ریاضی بهینهسازی اغلب منجر به یک فرمول یا دستورالعمل خاص برای حل هر مسئله میشوند. در حالی که روشهای هوشمند دستورالعملهایی هستند که به صورت کلی میتوانند در حل هر مسئلهای به کار گرفته شوند. این نکته را پس از آشنایی با خود الگوریتم بیشتر و بهتر خواهید دید.
الگوریتمهای ژنتیک از اصول انتخاب طبیعی داروین برای یافتن فرمول بهینه جهت پیشبینی یا تطبیق الگو استفاده میکنند. الگوریتمهای ژنتیک اغلب گزینه خوبی برای تکنیکهای پیشبینی بر مبنای رگرسیون هستند.
برای مثال اگر بخواهیم نوسانات قیمت نفت را با استفاده از عوامل خارجی و ارزش رگرسیون خطی ساده مدل کنیم، این فرمول را تولید خواهیم کرد : قیمت نفت در زمان t = ضریب 1 نرخ بهره در زمان t + ضریب 2 نرخ بیکاری در زمان t + ثابت 1 . سپس از یک معیار برای پیدا کردن بهترین مجموعه ضرایب و ثابتها جهت مدل کردن قیمت نفت استفاده خواهیم کرد. در این روش 2 نکته اساسی وجود دارد. اول این که روش خطی است و مسئله دوم این است که ما به جای اینکه در میان "فضای پارامترها" جستجو کنیم، پارامترهای مورد استفاده را مشخص کردهایم.
با استفاده از الگوریتمهای ژنتیک ما یک ابر فرمول یا طرح، تنظیم میکنیم که چیزی شبیه "قیمت نفت در زمان t تابعی از حداکثر 4 متغیر است" را بیان میکند. سپس دادههایی برای گروهی از متغیرهای مختلف، شاید در حدود 20 متغیر فراهم خواهیم کرد. سپس الگوریتم ژنتیک اجرا خواهد شد که بهترین تابع و متغیرها را مورد جستجو قرار میدهد. روش کار الگوریتم ژنتیک به طور فریبندهای ساده، خیلی قابل درک و به طور قابل ملاحظهای روشی است که ما معتقدیم حیوانات آنگونه تکامل یافتهاند. هر فرمولی که از طرح داده شده بالا تبعیت کند فردی از جمعیت فرمولهای ممکن تلقی میشود.
متغیرهایی که هر فرمول دادهشده را مشخص میکنند به عنوان یکسری از اعداد نشان دادهشدهاند که معادل [دی ان ای|دی.ان.ای](DNA) آن فرد را تشکیل میدهند.
موتور الگوریتم ژنتیک یک جمعیت اولیه از فرمول ایجاد میکند. هر فرد در برابر مجموعهای از دادههای مورد آزمایش قرار میگیرند و مناسبترین آنها (شاید 10 درصد از مناسبترینها) باقی میمانند؛ بقیه کنار گذاشته میشوند. مناسبترین افراد با هم جفتگیری (جابجایی عناصر دی ان ای) و تغییر (تغییر تصادفی عناصر دی ان ای) کردهاند. مشاهده میشود که با گذشت از میان تعداد زیادی از نسلها، الگوریتم ژنتیک به سمت ایجاد فرمولهایی که دقیقتر هستند، میل میکنند. در حالی که شبکههای عصبی هم غیرخطی و غیرپارامتریک هستند، جذابیت زیاد الگوریتمهای ژنتیک این است نتایج نهایی قابل ملاحظهترند. فرمول نهایی برای کاربر انسانی قابل مشاهده خواهد بود، و برای ارائه سطح اطمینان نتایج میتوان تکنیکهای آماری متعارف را بر روی این فرمولها اعمال کرد. فناوری الگوریتمهای ژنتیک همواره در حال بهبود است و برای مثال با مطرح کردن معادله ویروسها که در کنار فرمولها و برای نقض کردن فرمولهای ضعیف تولید میشوند و در نتیجه جمعیت را کلاً قویتر میسازند.
مختصراً گفته میشود که الگوریتم ژنتیک (یا GA) یک تکنیک برنامهنویسی است که از تکامل ژنتیکی به عنوان یک الگوی حل مسئله استفاده میکند. مسئلهای که باید حل شود ورودی است و راه حلها طبق یک الگو کدگذاری میشوند که تابع fitness نام دارد و هر راه حل کاندید را ارزیابی میکند که اکثر آنها به صورت تصادفی انتخاب میشوند.
الگوریتم ژنتیک (GA) یک تکنیک جستجو در علم رایانه برای یافتن راه حل بهینه و مسائل جستجو است. الگوریتمهای ژنتیک یکی از انواع الگوریتمهای تکاملیاند که از علم زیستشناسی مثل وراثت، جهش، [انتخاب ناگهانی(زیستشناسی)|انتخاب ناگهانی]، انتخاب طبیعی و ترکیب الهام گرفته شده.
عموماً راهحلها به صورت 2 تایی 0 و 1 نشان داده میشوند، ولی روشهای نمایش دیگری هم وجود دارد. تکامل از یک مجموعه کاملاً تصادفی از موجودیتها شروع میشود و در نسلهای بعدی تکرار میشود. در هر نسل، مناسبترینها انتخاب میشوند نه بهترینها.
یک راهحل برای مسئله مورد نظر، با یک لیست از پارامترها نشان داده میشود که به آنها کروموزوم یا ژنوم میگویند. کروموزومها عموماً به صورت یک رشته ساده از دادهها نمایش داده میشوند، البته انواع ساختمان دادههای دیگر هم میتوانند مورد استفاده قرار گیرند. در ابتدا چندین مشخصه به صورت تصادفی برای ایجاد نسل اول تولید میشوند. در طول هر نسل، هر مشخصه ارزیابی میشود وارزش تناسب (fitness) توسط تابع تناسب اندازهگیری میشود.
گام بعدی ایجاد دومین نسل از جامعه است که بر پایه فرآیندهای انتخاب، تولید از روی مشخصههای انتخاب شده با عملگرهای ژنتیکی است: اتصال کروموزومها به سر یکدیگر و تغییر.
برای هر فرد، یک جفت والد انتخاب میشود. انتخابها به گونهایاند که مناسبترین عناصر انتخاب شوند تا حتی ضعیفترین عناصر هم شانس انتخاب داشته باشند تا از نزدیک شدن به جواب محلی جلوگیری شود. چندین الگوی انتخاب وجود دارد: چرخ منگنهدار(رولت)، انتخاب مسابقهای (Tournament) ،... .
معمولاً الگوریتمهای ژنتیک یک عدد احتمال اتصال دارد که بین 0.6 و 1 است که احتمال به وجود آمدن فرزند را نشان میدهد. ارگانیسمها با این احتمال دوباره با هم ترکیب میشوند. اتصال 2 کروموزوم فرزند ایجاد میکند، که به نسل بعدی اضافه میشوند. این کارها انجام میشوند تا این که کاندیدهای مناسبی برای جواب، در نسل بعدی پیدا شوند. مرحله بعدی تغییر دادن فرزندان جدید است. الگوریتمهای ژنتیک یک احتمال تغییر کوچک و ثابت دارند که معمولاً درجهای در حدود 0.01 یا کمتر دارد. بر اساس این احتمال، کروموزومهای فرزند به طور تصادفی تغییر میکنند یا جهش مییابند، مخصوصاً با جهش بیتها در کروموزوم ساختمان دادهمان.
این فرآیند باعث به وجود آمدن نسل جدیدی از کروموزومهایی میشود، که با نسل قبلی متفاوت است. کل فرآیند برای نسل بعدی هم تکرار میشود، جفتها برای ترکیب انتخاب میشوند، جمعیت نسل سوم به وجود میآیند و .... این فرآیند تکرار میشود تا این که به آخرین مرحله برسیم.
شرایط خاتمه الگوریتمهای ژنتیک عبارتند از:
قبل از این که یک الگوریتم ژنتیک برای یک مسئله اجرا شود، یک روش برای کد کردن ژنومها به زبان کامپیوتر باید به کار رود. یکی از روشهای معمول کد کردن به صورت رشتههای باینری است: رشتههای 0و1. یک راه حل مشابه دیگر کدکردن راه حلها در آرایهای از اعداد صحیح یا اعشاری است، که دوباره هر جایگاه یک جنبه از ویژگیها را نشان میدهد. این راه حل در مقایسه با قبلی پیچیدهتر و مشکلتر است. مثلاً این روش توسط استفان کرمر، برای حدس ساختار 3 بعدی یک پروتئین موجود در آمینو اسیدها استفاده شد. الگوریتمهای ژنتیکی که برای آموزش شبکههای عصبی استفاده میشوند، از این روش بهره میگیرند.
سومین روش برای نمایش صفات در یک GA یک رشته از حروف است، که هر حرف دوباره نمایش دهنده یک خصوصیت از راه حل است.
خاصیت هر 3تای این روشها این است که آنها تعریف سازندهایی را که تغییرات تصادفی در آنها ایجاد میکنند را آسان میکنند: 0 را به 1 وبرعکس، اضافه یا کم کردن ارزش یک عدد یا تبدیل یک حرف به حرف دیگر.

یک روش دیگر که توسط John Koza توسعه یافت، برنامهنویسی ژنتیک (genetic programming)است. که برنامهها را به عنوان شاخههای داده در ساختار درخت نشان میدهد. در این روش تغییرات تصادفی میتوانند با عوض کردن عملگرها یا تغییر دادن ارزش یک گره داده شده در درخت، یا عوض کردن یک زیر درخت با دیگری به وجود آیند.
در هر مسئله قبل از آنکه بتوان الگوریتم ژنتیک را برای یافتن یک پاسخ به کار برد به دو عنصر نیاز است:در ابتدا روشی برای ارائه یک جواب به شکلی که الگوریتم ژنتیک بتواند روی آن عمل کند لازم است. در روش سنتی یک جواب به صورت یک رشته از بیتها، اعداد یا نویسهها نمایش داده میشود.دومین جزء اساسی الگوریتم ژنتیک روشی است که بتواند کیفیت هر جواب پیشنهاد شده را با استفاده از توابع تناسب محاسبه نماید. مثلاً اگر مسئله هر مقدار وزن ممکن را برای یک کوله پشتی مناسب بداند بدون اینکه کوله پشتی پاره شود، (مسئله کوله پشتی را ببینید) یک روش برای ارائه پاسخ میتواند به شکل رشته ای از بیتهای ? و? در نظر گرفته شود، که ? یا ? بودن نشانه اضافه شدن یا نشدن وزن به کوله پشتی است.تناسب پاسخ، با تعیین وزن کل برای جواب پیشنهاد شده اندازه گیری میشود.
1 Genetic Algorithm
2 begin 3 Choose initial population
4 repeat 5 Evaluate the individual fit nesses of a certain proportion of the population
6 Select pairs of best-ranking individuals to reproduce
7 Apply crossover operator
8 Apply mutation operator
9 until terminating condition
10 end

در دهه هفتاد میلادی دانشمندی از دانشگاه میشیگان به نام جان هلند ایده استفاده از الگوریتم ژنتیک را در بهینهسازیهای مهندسی مطرح کرد. ایده اساسی این الگوریتم انتقال خصوصیات موروثی توسط ژنهاست. فرض کنید مجموعه خصوصیات انسان توسط کروموزومهای او به نسل بعدی منتقل میشوند. هر ژن در این کروموزومها نماینده یک خصوصیت است. بعنوان مثال ژن 1 میتواند رنگ چشم باشد، ژن 2 طول قد، ژن 3 رنگ مو و الی آخر. حال اگر این کروموزوم به تمامی، به نسل بعد انتقال یابد، تمامی خصوصیات نسل بعدی شبیه به خصوصیات نسل قبل خواهد بود. بدیهیست که در عمل چنین اتفاقی رخ نمیدهد. در واقع بصورت همزمان دو اتفاق برای کروموزومها میافتد. اتفاق اول جهش (Mutation) است. "جهش" به این صورت است که بعضی ژنها بصورت کاملاً تصادفی تغییر میکنند. البته تعداد این گونه ژنها بسیار کم میباشد اما در هر حال این تغییر تصادفی همانگونه که پیشتر دیدیم بسیار مهم است. مثلاً ژن رنگ چشم میتواند بصورت تصادفی باعث شود تا در نسل بعدی یک نفر دارای چشمان سبز باشد. در حالی که تمامی نسل قبل دارای چشم قهوهای بودهاند. علاوه بر "جهش" اتفاق دیگری که میافتد و البته این اتفاق به تعداد بسیار بیشتری نسبت به "جهش" رخ میدهد چسبیدن ابتدای یک کروموزوم به انتهای یک کروموزوم دیگر است. این مسأله با نام Crossover شناخته میشود. این همان چیزیست که مثلاً باعث میشود تا فرزند تعدادی از خصوصیات پدر و تعدادی از خصوصیات مادر را با هم به ارث ببرد و از شبیه شدن تام فرزند به تنها یکی از والدین جلوگیری میکند.
روشهای مختلفی برای الگوریتمهای ژنتیک وجود دارند که میتوان برای انتخاب ژنومها از آنها استفاده کرد. اما روشهای لیست شده در پایین از معمولترین روشها هستند.
مناسبترین عضو هر اجتماع انتخاب میشود.Elitist Selection
یک روش انتخاب است که در آن عنصری که عدد برازش (تناسب) بیشتری داشته باشد، انتخاب میشود. در واقع به نسبت عدد برازش برای هر عنصر یک احتمال تجمعی نسبت میدهیم و با این احتمال است که شانس انتخاب هر عنصر تعیین می شود.
Roulette Selection
به موازات افزایش متوسط عدد برازش جامعه، سنگینی انتخاب هم بیشتر میشود و جزئیتر. این روش وقتی کاربرد دارد که مجموعه دارای عناصری باشد که عدد برازش بزرگی دارند و فقط تفاوتهای کوچکی آنها را از هم تفکیک میکند.Scaling Selection
یک زیر مجموعه از صفات یک جامعه انتخاب میشوند و اعضای آن مجموعه با هم رقابت میکنند و سرانجام فقط یک صفت از هر زیرگروه برای تولید انتخاب میشوند.Tournament Selection
بعضی از روشهای دیگر عبارتند از:Hierarchical Selection, Steady-State Selection, Rank Selection, Tournament Selection
نوشته شده توسط لادن در جمعه 90/1/26 و ساعت 9:38 صبح | نظرات دیگران()طراحی یک شبکه ساده
کابل های (UTP (Unshielded Twisted Pair
کابل UTP یکی از متداولترین کابل های استفاده شده در شبکه های مخابراتی و کامپیوتری است . از کابل های فوق ، علاوه بر شبکه های کامپیوتری در سیستم های تلفن نیز استفاده می گردد ( CAT1 ). شش نوع کابل UTP متفاوت وجود داشته که می توان با توجه به نوع شبکه و اهداف مورد نظر از آنان استفاده نمود . کابل CAT5 ، متداولترین نوع کابل UTP محسوب می گردد.
توضیحات : تقسیم بندی هر یک از گروه های فوق بر اساس نوع کابل مسی و Jack انجام شده است .از کابل های CAT1 ، به دلیل عدم حمایت ترافیک مناسب، در شبکه های کامپیوتری استفاده نمی گردد . از کابل های گروه CAT2, CAT3, CAT4, CAT5 و CAT6 در شبکه ها استفاده می گردد .کابل های فوق ، قادر به حمایت از ترافیک تلفن و شبکه های کامپیوتری می باشند . از کابل های CAT2 در شبکه های Token Ring استفاده شده و سرعتی بالغ بر 4 مگابیت در ثانیه را ارائه می نمایند . برای شبکه هائی با سرعت بالا ( یکصد مگا بیت در ثانیه ) از کابل های CAT5 و برای سرعت ده مگابیت در ثانیه از کابل های CAT3 استفاده می گردد. در کابل های CAT3 ,CAT4 و CAT5 از چهار زوج کابل مسی استفاده شده است . CAT5 نسبت به CAT3 دارای تعداد بیشتری پیچش در هر اینچ می باشد . بنابراین این نوع از کابل ها سرعت و مسافت بیشتر ی را حمایت می نمایند . از کابل های CAT3 و CAT4 در شبکه هایToken Ring استفاده می گردد . حداکثر مسافت در کابل های CAT3 ، یکصد متر است . حداکثر مسافت در کابل های CAT4 ، دویست متر است . کابل CAT6 با هدف استفاده در شبکه های اترنت گیگابیت طراحی شده است . در این رابطه استانداردهائی نیز وجود دارد که امکان انتقال اطلاعات گیگابیت بر روی کابل های CAT5 را فراهم می نماید( CAT5e ) .کابل های CAT6 مشابه کابل های CAT5 بوده ولی بین 4 زوج کابل آنان از یک جداکننده فیزیکی به منظور کاهش پارازیت های الکترومغناطیسی استفاده شده و سرعتی بالغ بر یکهزار مگابیت در ثانیه را ارائه می نمایند.
در شبکه lan شرکت از کابل cat6 از نوع utp برای مسافت های زیر زیر 100 متر و برای بالاتر از 100 از نوع sftp استفاده شده است
تصویر کابل شبکه و سوکت Rj45 چهت اتصالات دستگهاهای شبکه
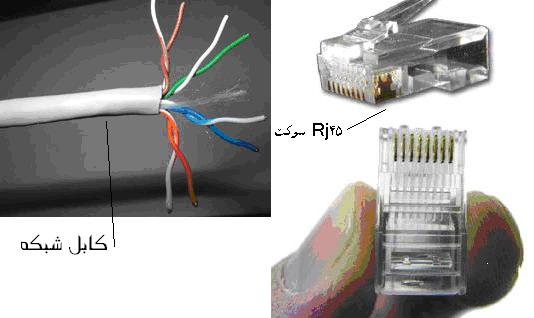
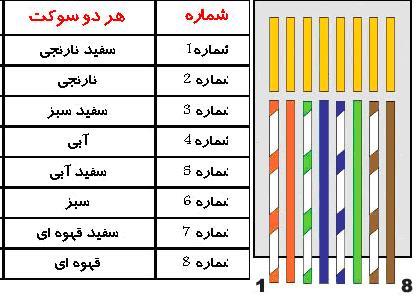
رنگ و شماره رشته های کابل شبکه
شماره گزاری از سمت مخالف خار سوکت(طرف تخت سوکت) و ازسمت چپ به راست صورت می گیرد
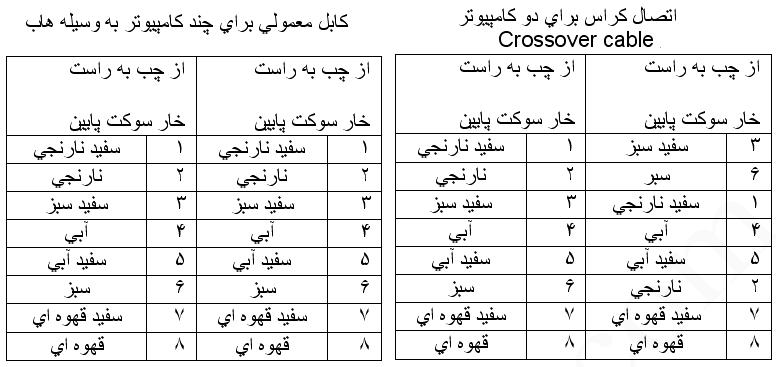
تهیه کابل کراس و کابل معمولی برای اتصال دو کامپیوتر و بدون استفاده از هاب سویچ از کابل کراس و برای اتصال چند کامپیوتر به هم از طریق هاب سویچ از کابل معمولی استفاده میشود
نوشته شده توسط علی در سه شنبه 90/1/23 و ساعت 4:53 صبح | نظرات دیگران()مسنجر کاملا فارسی


نوشته شده توسط علی در دوشنبه 90/1/22 و ساعت 2:32 عصر | نظرات دیگران()





.jpg)


